数据可视化:把玩一下seaborn(一)
最近刚开始学习数据可视化,第一个任务就是了解并完成seaborn(一个python处理数据可视化的库)的官方教程,其他数据可视化的内容会后续更新。seaborn在调用数据的时候会有一些数据库相关的操作,例如
data=data=diamonds.sort_values("color")这里就不解释了
环境搭建:
- 下载Anaconda搭建Python环境
- 下载类库Numpy, SciPy, matplotlib, pandas 和 seaborn
引入需要的库,设置一下显示网格的样式
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns数据关系可视化
接下来我们使用seaborn最常用的方法relplot()实现散点图scatterplot()和线图lineplot()
散点图 Scatter plots
首先可以引入seaborn中自带事例子数据集“tips”,这个数据集的属性有
时间数据 week
账单: 总消费,小费 total_bill, tips
消费者性别 sex
消费者是否抽烟 smoker
…
下面很多例子使用了tips数据集,不会再特别指出
sns.set(style="darkgrid") # 设置样式为网格
tips = sns.load_dataset("tips")其实seaborn中有很多画散点图的方法其中一种是scatterplot(),使用方法是把数据集中的集合分配给方法中的属性,这样不同集合就会使用散点图中不同属性的样式展示出来如下面实例中的色调属性hue获取了数据集中的smoker集合,这样集合中的数据差异就可以通过色调的不同展示出来,其他同理.
sns.relplot(x="total_bill", y="tip", size="size",hue="smoker", palette="ch:r=-.5,l=.75", style="time",sizes=(15, 200), data=tips);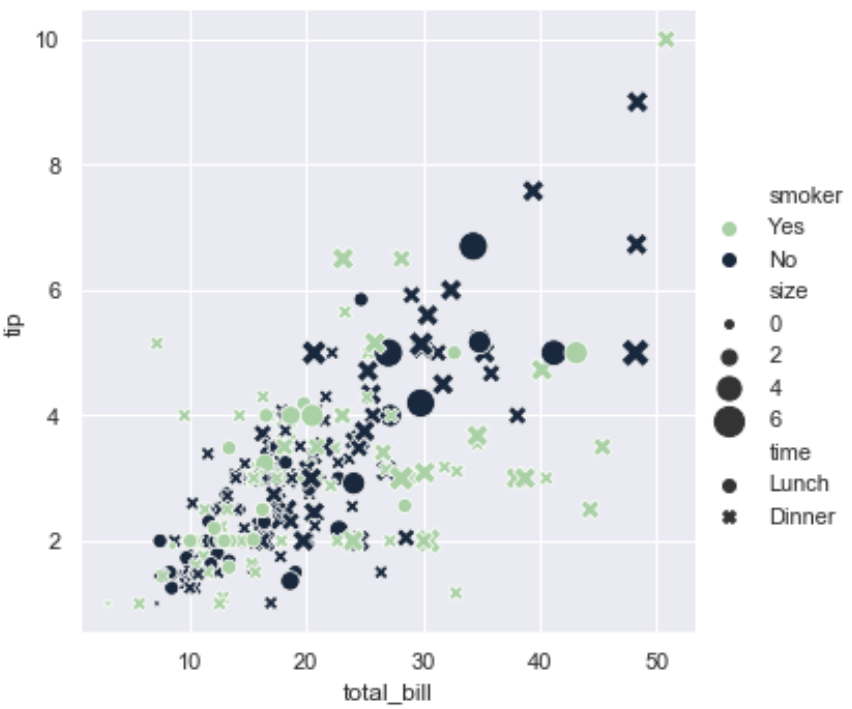
scatterplot是relplot的默认方法所以不需要单独设置,具体属性可以去scatterplot()的Api查看.
折线图强调连续性 Emphasizing continuity with line plots
下面介绍一下relplot里的第二个方法lineplot,前面说过默认方法是scatterplot所以要设置属性kind=lineplot启用折线图,这个方法默认sort=true将x轴数据与y轴数据按顺序对应起来.
fmri = sns.load_dataset("fmri")
sns.relplot(x="timepoint",
y="signal",
hue="region",
style="event",
dashes=True, # 开启显示虚线
markers=True, # 显示标记
# ci="sd" # 显示标准偏差,默认是显示置信区间,None关闭显示
kind="line",
data=fmri);这里我们引入一个新的fmri数据集
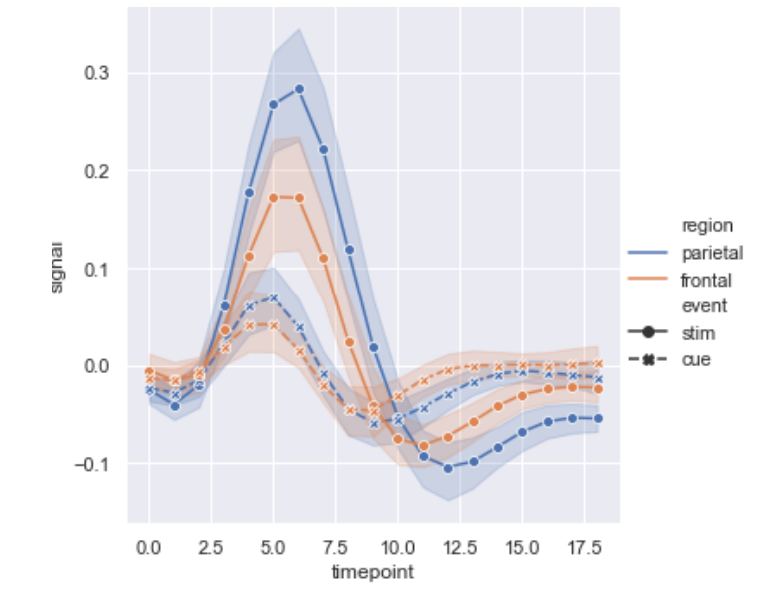
同时显示多了图表
用到relplot的属性是col和col_wrap自动分行,同理也可以用row属性设置列.
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject",
col_wrap=5, # 设置每行显示图表数量
height=3, # 每个图表的高度
kind="line",
data=fmri.query("region == 'frontal'"));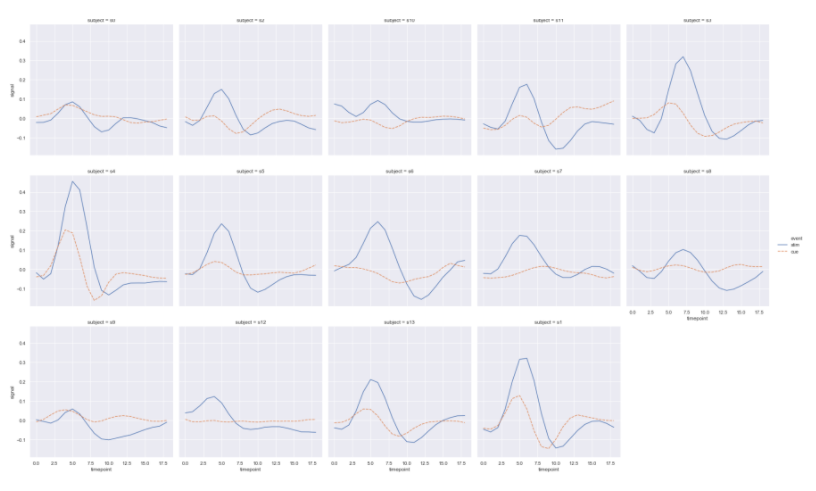
数据种类的可视化 Plotting with categorical data
对数据进行分类可视化用到的方法是catplot(),和数据关系可视化类似,catplot()也有多种分类(kind),包括散点图(strip,swarm),分布图(box,violin,boxen)和柱状图(point,bar,count).
sns.set(style="ticks", color_codes=True) #设置一下样式散点图 categories scatterplots
除了种类外,散点图能精确的显示数据的分布,散点图默认显示方式是stript,例如下面的例子,
tips = sns.load_dataset("tips") #载入数据
sns.catplot(x="day", y="total_bill", data=tips); 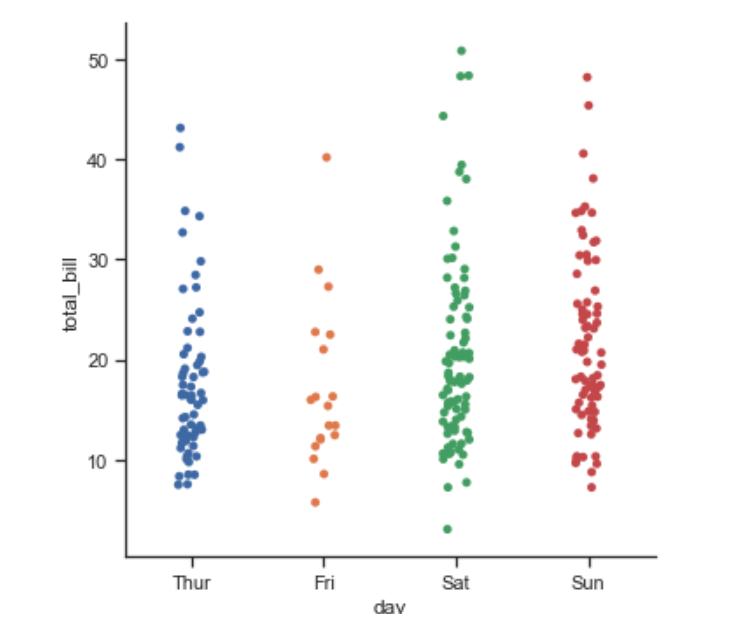
可以发现上面有些数据重叠在一起了,解决这个问题可以使用jitter属性,也可使用另一种散点图swarm,它自动使用算法区分出可能重叠的数据.需要注意的是可以使用order来控制顺序.下面的例子可以看出
sns.catplot(x="total_bill", y="day", hue="time", kind="swarm", order=["Sun", "Sat","Fri","Thur"], data=tips);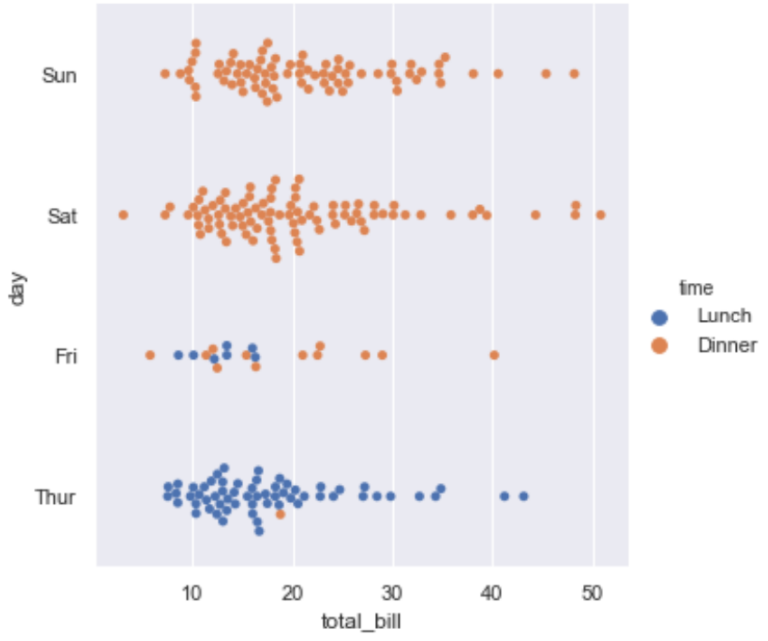
分布图 Distributions of observations within categories
数据量太大的时候,散点图显示不同种类的分布情况非常恐怖,所以可以使用分布图来观察不同种类数据的分布情况,具体代码就不贴了,只需要更改一下kind属性就可以了,下面分别看一下box,boxen,violin三种情况不同的显示风格:
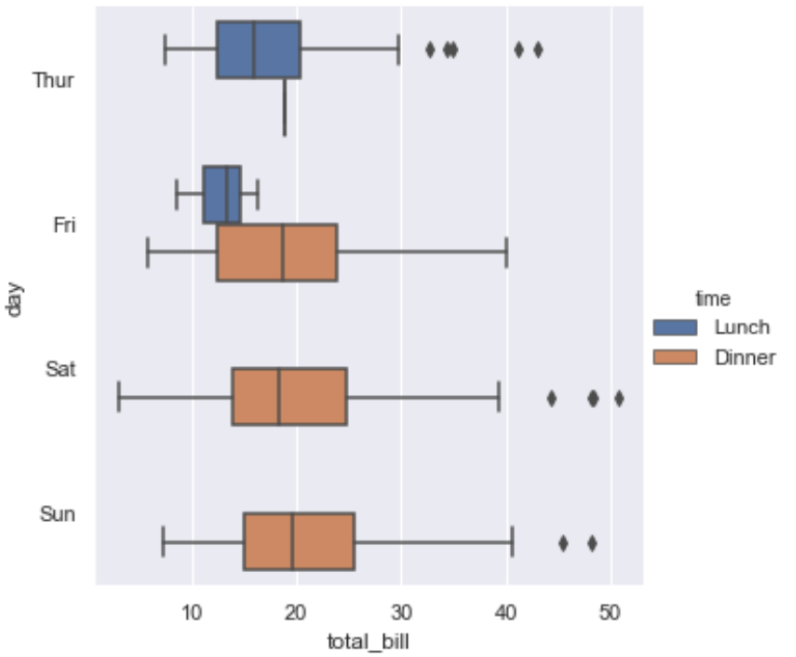
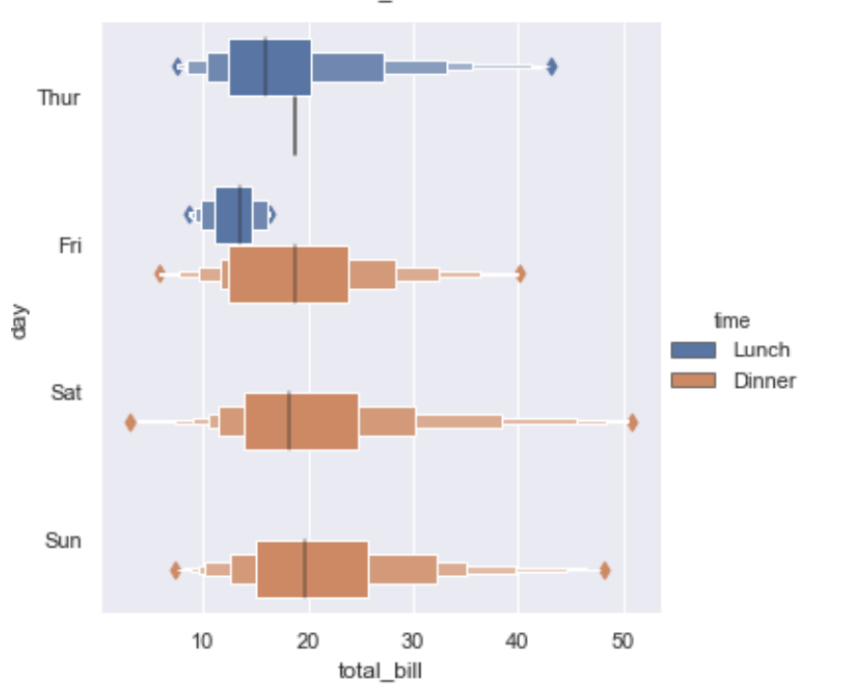
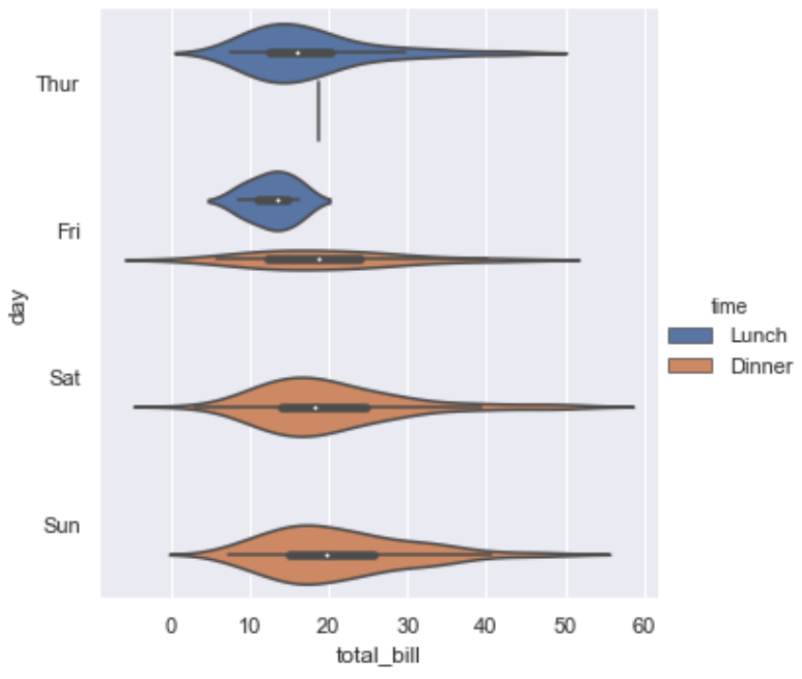
其中要重点说一下violin方法使用了KDE,因此有一些额外的属性可以设置,具体可以查看一下api例如:
sns.catplot(x="total_bill", y="day", hue="sex",bw=.4, cut=2, inner="stick",
kind="violin", split=True, data=tips);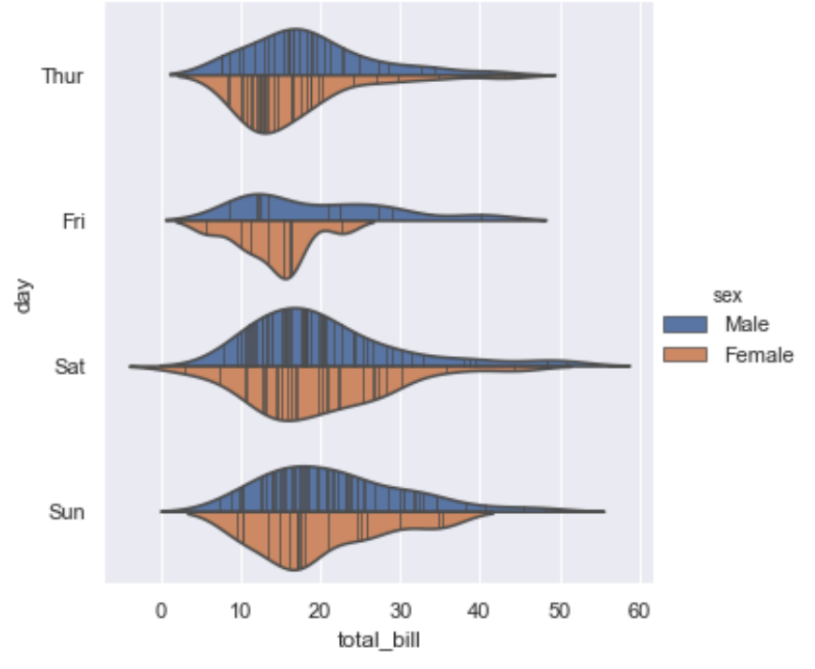
合并图表
另外看一下如何将两个不同类型的图表合为一个,例如下面我们将violin和swarm类型的图表在一张图里展示:
g = sns.catplot(x="day", y="total_bill", kind="violin", inner=None, data=tips)
sns.swarmplot(x="day", y="total_bill", color="k", size=3, data=tips, ax=g.ax);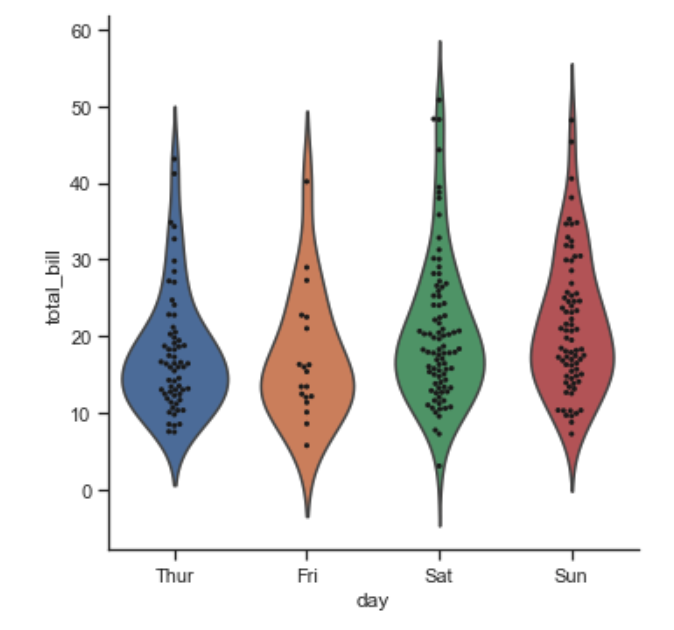
数据估计
很多情况我们是不需要特别精确的数据信息的,只需要了解各个分类的走势和差异性,这个时候柱状图bar和点状图point可以展示的信息更简洁明了.
例如这里我们引入一个新的数据集titanic来分析一下泰坦尼克号上不同仓位的乘客的生存率
titanic = sns.load_dataset("titanic")首先下面看一下柱状图,这张图是可以直观的比较出各个仓位的生存率,需要指出的是柱状图的矩形边框也可以设置颜色.
sns.catplot(x="class",
y="survived", hue="sex",
palette={"male": "g", "female": "m"}, # 设置hue属性显示的颜色
edgecolor=".6",
kind="bar",
data=titanic);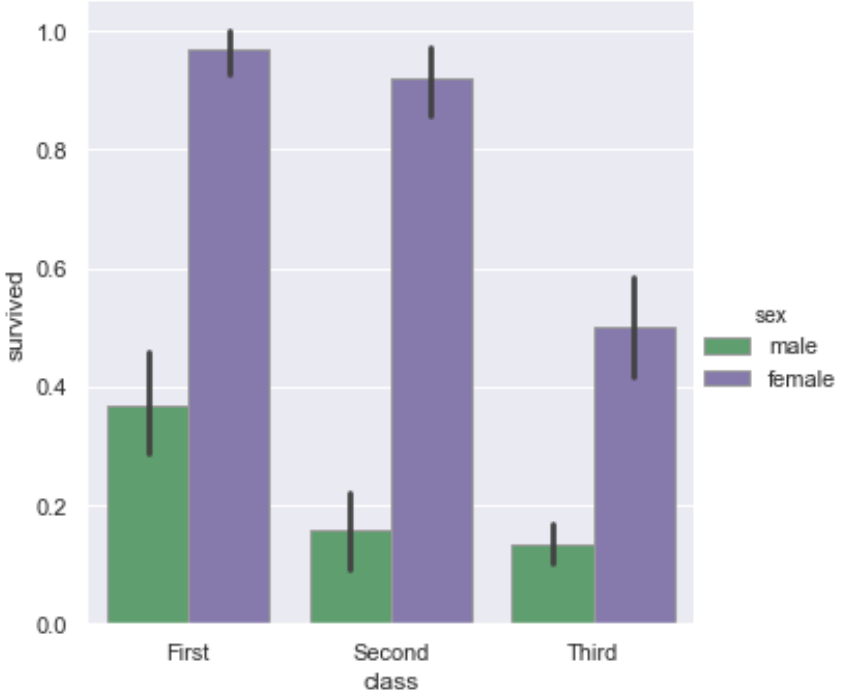
点状图可以设置的属性也有很多,比如线的样式,点的样式等等
sns.catplot(x="class", y="survived", hue="sex",
palette={"male": "g", "female": "m"},
markers=["^", "o"], linestyles=["-", "--"],
kind="point", data=titanic);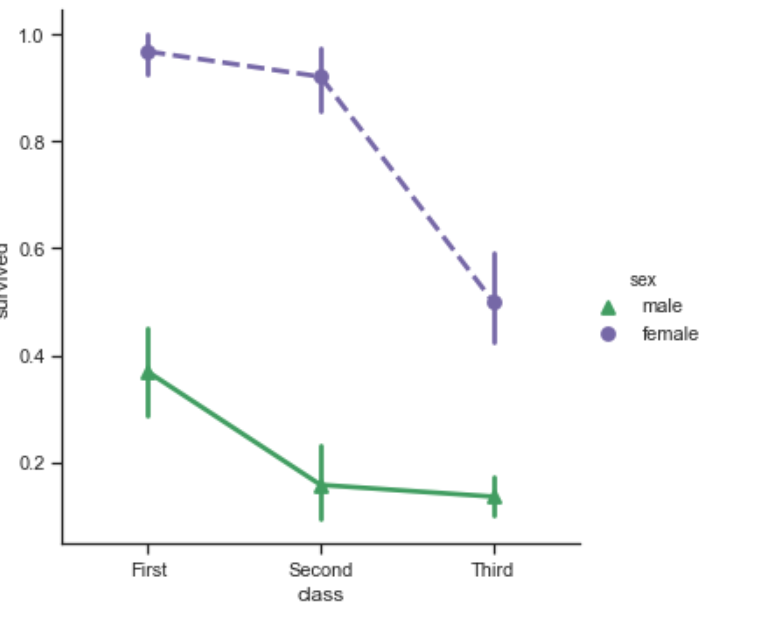
图表的大小控制
设置图表的大小可以使用matplotlib里的plt.subplots(figsize=(width,height))
想要改变图表各个轴的精度可以使用set方法参照下面的实例
g = sns.catplot(x="fare", y="survived", row="class",
kind="box", orient="h", height=1.5, aspect=4,
data=titanic.query("fare > 0"))
g.set(xscale="log"); # x轴以对数形式显示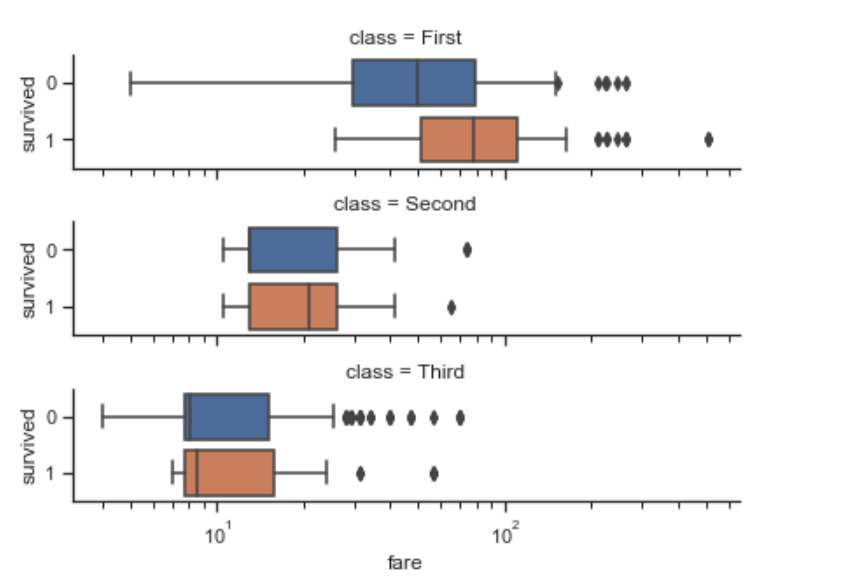
参考资料:
 Wechat
Wechat- Paypal
- Alipay





